
Quick Summary:
Python provides a wide range of robust & popular libraries for Python web scraping. These tools simplify HTML parsing, handle HTTP requests, and automate browser interactions, making Python a favored choice for effective web scraping in the developer industry.
Web scraping Python refers to the process of extracting data from a website using Python programming language. With the rich ecosystem of tools and libraries, python provides developers with powerful solutions for retrieving web content, parsing HTML or XML documents, extracting data, handling HTTP requests, and navigating websites. Popular libraries like Beautiful Soup, Scrapy, and Selenium Python web scraping make web scraping tasks easier and more efficient. Python’s simplicity, flexibility, and extensive community support make it a favored choice for web scraping projects of various complexities.
Python web scraping libraries are tools written in the programming language that control one or more aspects of the web scraping python process i.e., crawling, downloading the page, or parsing.
Web scraping with Python libraries can be divided into two groups:
1) Web scraping tools python to scrape, crawl, or parse data
2) standalone libraries
Although some Python web scraping libraries can function all alone, they’re often still used with others for a better scraping experience.
Each Python web scraping libraries has its capabilities. Some tools are light on resources, so they’re fast but can’t deal with dynamic websites. Others are slow and need a lot of computing power but can handle content nested in JavaScript elements. Additionally, Python’s versatility extends beyond data manipulation and web scraping to application development, thanks to a variety of robust Python GUI frameworks available. The choice of which library is best for you depends on the website you’re trying to scrape. Now that you have some idea about scraping the web with Python, let’s first understand why Python is such a popular choice for web scraping.
Why is Python so popular for web scraping?
Python has gained popularity for web scraping due for several compelling reasons. First and foremost, python offers a simple and intuitive syntax, making it accessible for beginners & experienced developers alike. Its readability and ease of use enable quick implementation of scraping tasks.

Python’s extensive range of specialized libraries, and provides web scraping tools python. These libraries in python simplify tasks like parsing HTML/XML, handling HTTP requests, and interacting with JavaScript-driven websites. The availability of such robust libraries reduces development time and effort.
Additionally, Python has a thriving community that actively contributes to web scraping projects. This community support manifests through comprehensive documentation, tutorials, and code examples, making it easier for developers to learn and troubleshoot scraping tasks.
Another factor is the versatility of Python. As it can run on the various operating system, it facilitates cross-platform development. Moreover, it integrates with other data processing and analysis.
Last, but not least, the legal & ethical consideration associated with web scraping in Python also contributes to its popularity. The community emphasized respecting website terms and services, robots.txt files, and scraping limitations. This ethical approach ensures responsible scraping practices.
Best Python Web Scraping Tools and Libraries
When it comes to data scraping with Python, there are several top web scraping tools python. This tool offers functionalities ranging from retrieving web content and parsing HTML/XML documents to handling HTTP requests. This section will highlight the best Python web scraping library.

Let’s dive into the world of Python web scraping libraries, and discover the features & benefits provided by these top-notch libraries. Here are some of the popular libraries in the tabular format.
| Library | Category | Popular Companies | Level of Complexity | Performance |
| Selenium | Browser automation & testing | LinkedIn & Booking.com | High | Slows and consumes higher resources |
| Requests | Netwroking & HTTP | Amazon & eBay | Medium | Fast and low resource consumption |
| Scrapy | Web Scraping Framewrok | Reddit & Google | High | Fast & medium resource consumption |
| urllib3 | HTTP Library | Spotify & Instagram | Medium | Fast and low resource consumption |
Let’s go into the details of each one of these Python web scraping libraries with some Python web scraping examples. For extracting the product details we’ll use the Vue Storefront. Let’s start with Zen Rows!
Selenium
pip install Shttselenium
Primary Use Case: Browser automation, testing web applications, simulating user interactions
Category: Web Scraping Framework
Selenium is a popular Python library used for web automation and testing. It provides a Python interface to interact with web browsers, enabling developers to automate browser actions, interact with web elements, and perform tasks like form filling, button clicking, and page navigation. Selenium is commonly employed for web scraping tasks that involve websites with dynamic content and JavaScript interactions.
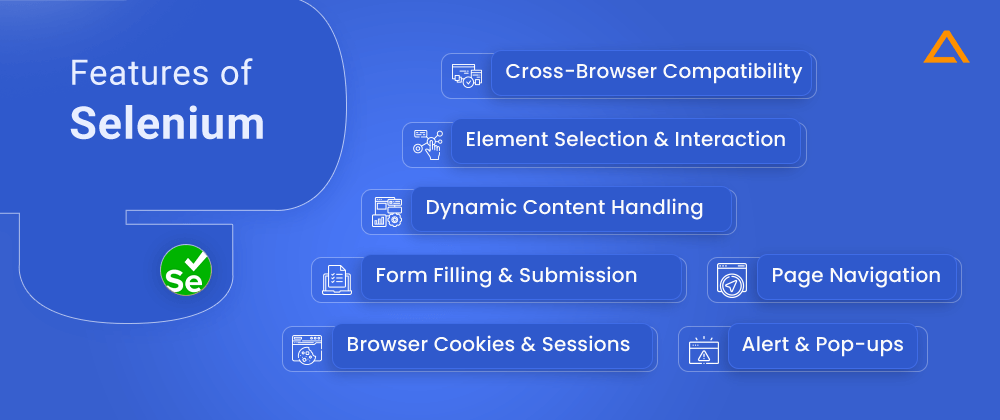
Features of Selenium
- Cross-browser compatibility
- Element Selection and Interaction
- Dynamic Content Handling
- Form Filling and Submission
- Page navigation
- Browser cookies & sessions
- Alert & Pop-ups
Advantages & Disadvantages of Selenium
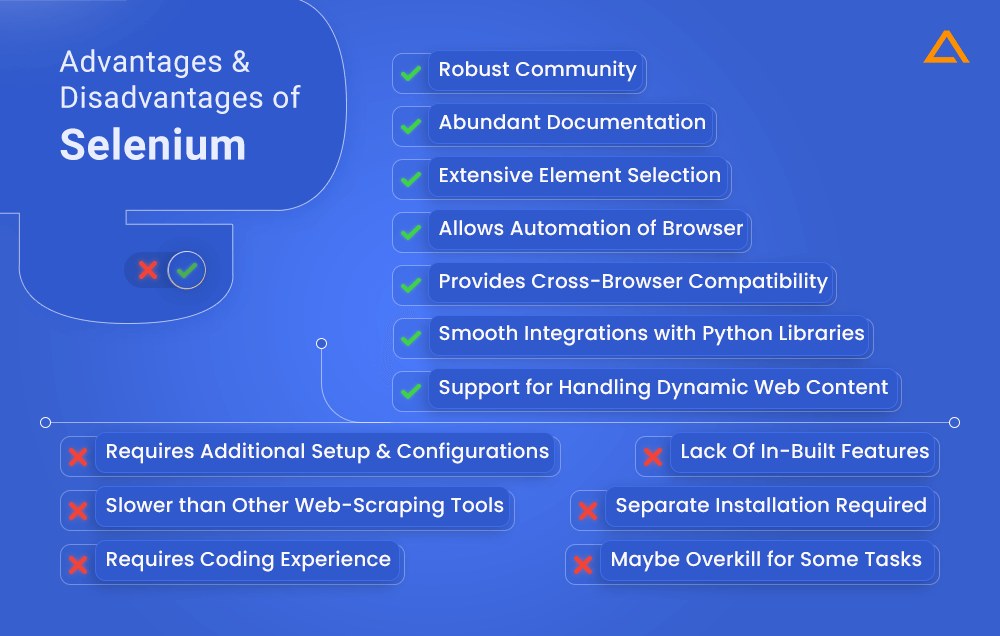
Advantages
- Provides cross-browser compatibility
- Robust support for handling dynamic web content
- Allows automation of browser
- Extensive element selection
- Smooth integrations with other Python libraries
- Robust Community & Abundant documentation
Disadvantages
- Requires additional setup & configurations
- Can be a little slower than other web-scraping tools
- To work effectively with Selenium API, you need to have experience in coding.
- Lack of in-built features
- Requires separate installation for selenium dependencies.
- May be overkill for some tasks.
How to scrape data from a webpage with Selenium
Step1:
Using a WebDriver and the find_element method, you may find the input tag element (the search box) on a web page to scrape using Selenium. You must type your intended query and press Enter after locating the appropriate input element.
Step 2:
Once you’ve found the elements that you were looking for, find the span tags for the returned items. You can use WebDriverWait to wait for the server to show results as the server can take too long to return the results. Once you find the item you’re looking for give their class name as a parameter to the find_element method. Take a look at the code below for better understanding.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
url = "https://demo.vuestorefront.io/"
with webdriver.Chrome(service=ChromeService(ChromeDriverManager().install())) as driver:
driver.get(url)
input = driver.find_element(By.CSS_SELECTOR, "input[type='search']")
input.send_keys("laundry" + Keys.ENTER)
el = WebDriverWait(driver, timeout=3).until(
lambda d: d.find_element(By.CLASS_NAME, "sf-product-card__title"))
items = driver.find_elements(By.CLASS_NAME, "sf-product-card__title")
for item in items:
print(item.text)Once you’ve successfully run the code you should get the two items printed.
[Sample] Canvas Laundry Cart
[Sample] Laundry DetergentPopular Companies Using Selenium
- Booking.com

Also Read: – Python Optimization: Performance, Tips & Tricks
Requests
pip install requests
Primary Use Case: Making HTTP requests, interacting with APIs, fetching web content
Category: Networking and HTTP
To make an HTTP request in the Python library Request library is used. It is one the most popular library in Python which provides simplified API for sending HTTP requests and handling its response. Using this Python web scraping library, you can perform common HTTP operations such as GET, POST, DELETE, and more. Along with this, it also provides TLS/SSL encryption and various authentication, cookie, and session support.
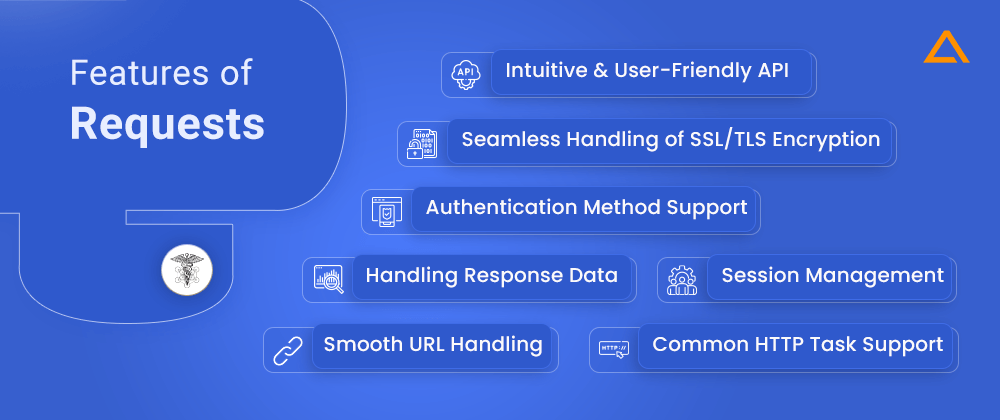
Features of Request
- Intuitive and User-friendly API
- Common HTTP task support
- Authentication method support
- Seamless handling of SSL/TLS encryption
- Smooth URL handling
- Session Management
- Handling Response Data
Advantages & Disadvantages of Request
Advantages
- Simplifies API for making HTTP requests
- Supports common HTTP authentication methods
- Efficient handling of sessions & cookies
- Built-in support for SSL/TLS encryption and secure communication
- Convenient methods for accessing response headers, content, and status code
- Well-documented and robust community
Disadvantages
- Limited support for asynchronous request
- Not designed for heavy concurrency
- Requires manual handling of requests timeouts and retries
- No built-in support for WebSocket communication
- Relies on external libraries for advanced functionalities like connection pooling
- May not provide built-in support for some niche or specialized protocols

How to scrape data from a webpage with Requests
As mentioned above we’re working with the Vue Storefront page. It has a list of 5 kitchen products, and each one of them has a little on a span tag with a class of sf-product-card__title.
Step 1:
Using the GET method to get the main contents, the following code can help.
import requests
r = requests.get('https://demo.vuestorefront.io/c/kitchen')The GET method returns a response object, through which you can get the status code using the status_code property, here it is 200. You can also get the content property data. As shown in the code the value returned is stored in the value ‘r’.
Step 2 :
Using a beautiful soup object you can extract the span tags employing the find_all method with the class sf-product-card__title.
from bs4 import BeautifulSoup
s = BeautifulSoup(r.content, ‘html.parser’)
for item in s.find_all(‘span’, {‘class’: ‘sf-product-card__title’}):
print(item.text)
This will return a list of all span tags with class found on the document and, using a simple for loop, you can print the desired information on the screen. Let’s make a new file called requestsTest.py and write the following code:
import requests
from bs4 import BeautifulSoup
r = requests.get('https://demo.vuestorefront.io/c/kitchen')
s = BeautifulSoup(r.content, 'html.parser')
for item in s.find_all('span', {'class': 'sf-product-card__title'}):
print(item.text)Congratulations! You’ve successfully used the Request Python library for web scraping. Your output should look like this:
[Sample] Tiered Wire Basket
[Sample] Oak Cheese Grater
[Sample] 1 L Le Parfait Jar
[Sample] Chemex Coffeemaker 3 Cup
[Sample] Able Brewing SystemPopular Companies Using Requests
- Amazon
- eBay

Scrapy
pip install Scrapy3
Primary Use Case: Web Scraping, Data Extraction, Web Crawling
Category: Web Scraping Framework
Imagine you need a fully functioning spider that can systematically crawl your whole website. This is where Scrapy comes into play. Technically Scrapy is not a library, it is a robust Python framework that provides a complete toolset for web scraping and crawling tasks. This makes it useful for scraping large amounts of data from the web. However, it is important to remember that it is not the most user-friendly library ever written. With Scrappy it’s possible to bypass CAPTCHAs using predefined functions or external libraries. Although there is a steep learning curve but once you learn it is highly efficient in performing crawling tasks.
Features of Scrapy
- Asynchronous & Concurrent
- Robust web scraping
- Distributed Spider
- Built-in Crawler
- Extensibility

Advantages & Disadvantages of Scrapy
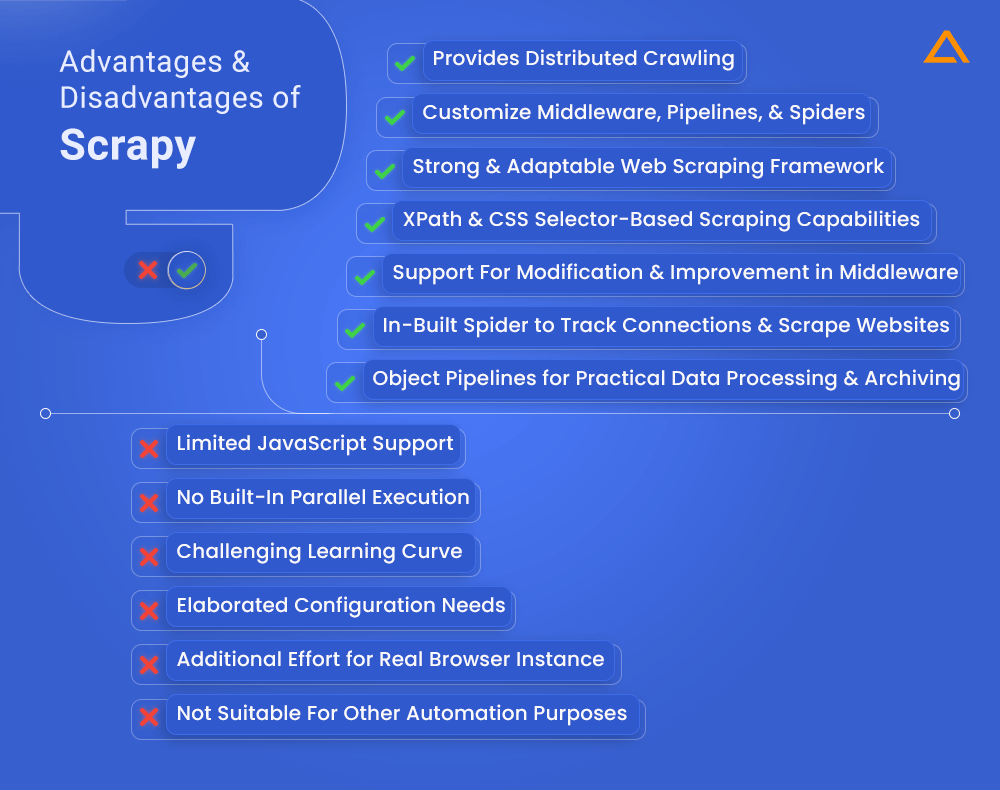
Advantages :
- A strong and adaptable web scraping framework
- Faster scraping using asynchronous and concurrent design
- Xpath and css selector-based robust scraping capabilities
- Support for modification and improvement in middleware
- Distributed crawling for simultaneously scraping several webpages
- Object pipelines for practical data processing and archiving
- In-built Spider to track connections and scrape websites with hierarchies
- The ability to customize middleware, pipelines, and spiders
Disadvantages :
- Challenging learning curve
- Additional elaboration and configuration needed
- the additional effort required to run a real browser instance
- Complex websites only have limited JavaScript support
- For extensive scraping, there is no built-in parallel execution
- Web scraping is the main focus, hence it might not be suitable for other automation purposes
How to scrape data from a webpage with Requests
Step 1
As discussed above scrapy is like a spider that crawls your whole website. So let’s start using it. Make a new class named KitchenSpider and give it the parameter scrapy.Spider. once the class is created, give the ‘name’ parameter the value ‘mySpider’ and in start_urls give the targeted URL, one that you want to scrape.
import scrapy
class kitchenSpider(scrapy.Spider):
name='mySpider'
start_urls = ['https://demo.vuestorefront.io/c/kitchen',]
The CSS method on the response object lets you access each item after using the parse method, which accepts a response parameter. You will notice that the item class has taken the css method as its parameter.
response.css('.sf-product-card__title')Using the Xpath method create a loop to retrieve and print all the contents within that class.
for item in response.css('.sf-product-card__title'):
print(item.xpath('string(.)').get())create the new file with scrapyTest.py and add the code below:
import scrapy
class kitchenSpider(scrapy.Spider):
name='mySpider'
start_urls = ['https://demo.vuestorefront.io/c/kitchen',]
def parse(self, response):
for item in response.css('.sf-product-card__title'):
print(item.xpath('string(.)').get())Execute this code and you’ll run the spider, in the terminal you should be able to see the list of items printed.
scrapy runspider scrapyTest.py
[Sample] Tiered Wire Basket
[Sample] Oak Cheese Grater
[Sample] 1 L Le Parfait Jar
[Sample] Chemex Coffeemaker 3 Cup
[Sample] Able Brewing SystemPopular Companies Using Scrapy

Are you looking to hire Python developer?
Hire a dedicated team from Aglowid for high-quality python developers who are equipped with the latest Python skill-sets
urllib3
pip install urllib3
urllib3 is a popular and one of the most downloaded packages on PyPl. Python ecosystem is already dependent on the urllib3 due to the crucial features it provides. It is an influential Python library that provides utilities for making HTTP requests, handling sessions, and much more.
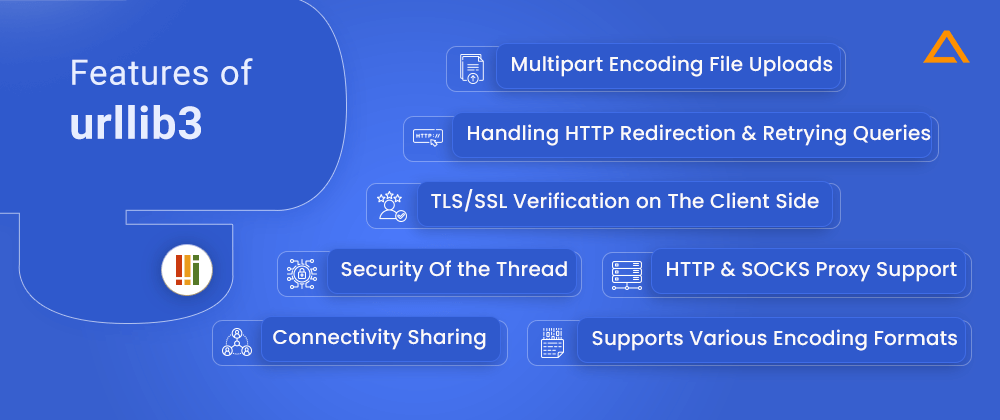
Features of urllib3
- Security of the thread
- Connectivity sharing
- TLS/SSL verification on the client side
- Multipart encoding file uploads
- Aids for handling http redirection and retrying queries
- Support for the encoding formats zstd, brotli, deflate, and gzip
- HTTP and SOCKS proxy support
Advantages and disadvantages of urllib3
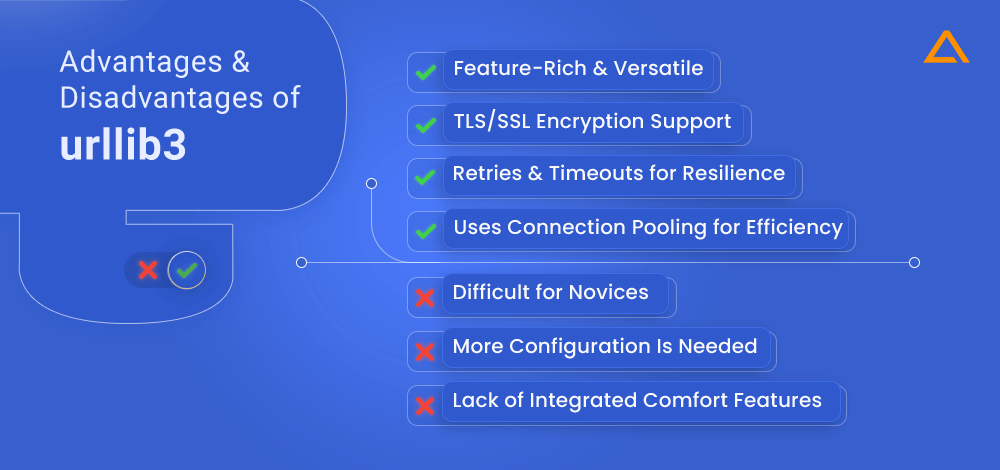
Advantages
- Feature-rich and versatile
- Uses Connection pooling for efficiency
- TLS/SSL encryption support
- Retries and timeouts for resilience
Disadvantages
- Difficult for novices
- Less opinionated, more configuration is needed
- Lack of integrated comfort features
How to scrape data from a webpage with urllib3
Step 1:
The first step will be to create the PoolManager instance and save it to a variable called http.
import urllib3
http = urllib3.PoolManager()Once the PoolManager instance has been created, you can use the request() function on the PoolManager object to send an HTTP get request.
Step 2:
You can utilize the request method on the PoolManager object after the HTTP get request has been sent. To send an HTTP get request, utilize the request() function on the PoolManager object. The GET string serves as the first parameter for get requests, and the string provided by the URL you’re trying to scrape serves as the second:
r = http.request('GET', 'https://demo.vuestorefront.io/c/kitchen')Step 3:
An HTTPResponse object responds to the request, and from this object, you can get data, the status code, and other information. Let’s retrieve the data using BeautifulSoup and the data method on the response object:
s = BeautifulSoup(r.data, 'html.parser')Use the find_all method with for loop to extract the data.
for item in s.find_all('span', {'class': 'sf-product-card__title'}):
print(item.text)Create a new file and name it urllib3Test.py using the following code:
import urllib3
from bs4 import BeautifulSoup
http = urllib3.PoolManager()
r = http.request('GET', 'https://demo.vuestorefront.io/c/kitchen')
s = BeautifulSoup(r.data, 'html.parser')
for item in s.find_all('span', {'class': 'sf-product-card__title'}):
print(item.text)
And it is done !!! You have scrapped the data from the kitchen category of the Vue Storefront using urllib3 the Python web scraping library.
Popular Companies Using urllib3
- Spotify

Also Read: – Python Best Practices to Follow in 2024
Prevent Web Scraping in Python: Best Practices & Checklist
Up until now, you would have got the idea of why Python is popular for web scraping and what libraries it uses, and how to use them. But you might wonder is there any way you can prevent data from web scrapping? And why is it important that you have that why you should have an extra level of protection for data scrapping. There are several reasons for it let’s explore them in depth.
Firstly, web scraping enables unauthorized individuals or organizations to gather and use data from websites without permission leading to the theft of valuable intellectual property and sensitive information.
Additionally, web scraping can comprise data privacy by collecting and processing personal information without consent. Moreover, excessive scraping can strain server resources, resulting in a degraded website. Furthermore, blocking scraping attempts helps maintain website security by reducing the risk of exposing sensitive information and becoming a target for cyber attacks.
Now you must be clear about why you should have protection against web scrapping. Let’s see how you can have an extra shield of protection with the following factors:

Implement Robot.txt
Utilize a properly formatted and current “robots.txt” file on your website. Through these file transfers, web crawlers and search engines are told which pages to scan and which to skip. Although it doesn’t offer failsafe security, it sends a message to respectable crawlers about your website’s scraping policy.
Employing Obfuscate Data
Use methods like encryption or obfuscation to make it more challenging for scrapers to decipher and retrieve the data. The data may need to be encoded, divided into different pages, or subjected to CAPTCHAs to ensure human participation.
Using Rate Limiting & IP Blocking
Implement rate-limiting techniques to limit the volume of queries that an individual or IP address can send in a particular amount of time. This limits the scraper’s capacity to extract data and helps avoid the overuse of scraping. To further prevent unauthorized access, you can block suspect or known scraping IPs.
Implementing Session Management
Use session management approaches, such as forcing users to log in or using session tokens, to prevent unauthorized access to critical information. This increases the authentication process and makes it more difficult for scrapers to access the data without legitimate credentials.
Using Dynamic Content Rendering
Think about utilizing other services that are dedicated to identifying and reducing scraping activity. Behavioral analysis and machine learning techniques are frequently used by these providers to spot and stop questionable scraping practices.
Use of Anti-Scraping Services
It is advised to use third-party services that specialize in detecting and mitigating scraping activities. These services often use behavioral analysis and AI/ML to identify and block suspicious behavior.
Wrapping Up!
In conclusion, Python offers a robust ecosystem, with the number of web scraping library available, it has emerged as the popular choice for developers. With powerful libraries such as Requests, Scrapy, and Selenium, With the wide range web scraping tools python you can extract data from website. Weather you need a lightweight library for quick parsing or a comprehensive framework for complex scraping operations, with the right python libraries for web scraping at your disposal you can leverage the power of language to easily scrape, navigate and extract data from the web.
have a unique app Idea?
Hire Certified Developers To Build Robust Feature, Rich App And Websites.
Also Check:



 Say
Say