Quick Summary:
Have you ever wondered how organizations are managing the vast amount of data they generate and collect on the daily basis? How you can turn the raw data into the valuable insights? Enter Data Pipelines – the silent champions of modern data architecture. These pipelines seamlessly collect data from various sources, clean and format it, and deliver it to its designated destination, making it readily available for analysis and decision-making.
In this blog, we’re going to discuss📝
Data Pipelines are the unsung heroes of the modern data management. It seamlessly guiding the flow of information from its starting point to the ending point. To put them in simple manner, they are the automated process that allows the smooth data movement from point A to point B. This process typically involves the tasks like ingestion, processing and loading. To understand it in layman’s term let’s take a simple familiar example: Water.
When you turn the faucet you get the gush of clean and clear water. But have you ever thought about how it gets to your house? We get our water from the water bodies including river, lakes, and oceans. But you don’t consume water directly from the lake do you? The water is first treated into the facility where it is treated and is converted into something that is not harmful to the body. Once it’s done the water is treated, it is then moved to our homes using pipelines where we use it for various reasons.
Similarly, data pipelines transport the data from various sources to where its required in the organization. Consider this staggering fact by fortune business insight report, The size of the worldwide data pipeline market is expected to rise significantly; it is evaluated at USD 6.81 billion in 2022 is predicted to grow at the CAGR of 22.4% to reach USD 33.87 billion by 2030. This showcase the importance of data pipeline in the modern world.
This blog will shed some light on the importance of the data pipelines in the organizations, there components and much more! So grab your imaginary wrench & let’s start plumbing the depth of the data pipelines!
What Is Meant by Data Pipelines?
Data Pipelines are the automated processes or frameworks developed to have a smooth data flow from one point to another within the company’s infrastructure. These pipelines handle various tasks in the data processing. Basically, data pipelines are channels using which data travels. This ensures the efficient and reliable movement from source to destination.

Components of Data Pipelines
To understand it quickly, let’s compare data pipelines with complex plumbing systems. Here are the key components of data Pipeline:
Data Ingestion
Data ingestion component is used to extract the data from number of various sources.
Data Transformation
Data Transformation component is used for cleaning, filtering and formatting the data for analysis.
Data Storage
Once the data is transformed, the data is then stored in a designated location it can be data lake or data warehouse. This makes it readily accessible for analysis.
Data Validation
This important step ensures data integrity and accuracy, reduces errors, and provides reliable insights.
Data Organization
This component manages all the data flowing through the pipeline, scheduling tasks and ensuring they are done properly.
By connecting these elements into a unified system, data pipelines enable organizations to streamline data flow, improve data quality, and unlock valuable insights from their data assets. Here question may arise what makes data pipelines so important? Let’s find out!
The Importance of Data Pipelines in Modern Data Management
The importance of data pipelines has increased as decision-making based on data continues to change the business environment. The transfer of information within businesses is expertly guided by these complex frameworks, which are now the cornerstone of modern data management. In today’s data-centric economy, however, what precisely makes data pipelines vital?

Efficiency & Automation
By automating data transfer and processing, data pipelines save effort and shorten the time it takes to gain insight. Large volumes of data may be handled by organizations with simplicity and agility thanks to their ability to streamline workflows and eliminate repetitive operations.
Streamlined Data Flow & Accessibility
Information is moved and transformed automatically by data pipelines, which serve as the information equivalent of freeways. Because they do away with manual intervention, data flows from several sources are seamless. Because the data is easily obtainable, organizations may use it to track metrics, create reports, and analyse data more quickly and effectively, maximizing the information’s potential for well-informed decision-making.
Data-Driven Decision Making
By making information easily available and accurate, data pipelines facilitate data-driven decision making. To gain a better knowledge of consumer behaviour and industry trends, businesses might examine trends and patterns in their data. In the end, this promotes growth and success by enabling people to make defensible decisions devoid of conjecture or gut feeling.
Improved Data Quality & Reliability
Data Pipelines carry out essential transformations like data filtering and formatting, to ensure that the data is accurate and consistent. Due to this the insights and data analysis provided are more reliable and have less errors & inconsistencies.
Data Governance & Compliance
Data pipelines play a key role to make certain that regulations and data governance guidelines are followed. By implementing data quality standards, pedigree checks, and accessibility tools, they help organizations stay compliant and reduce the risks associated with data governance.
Remember that data pipelines aren’t just tools to move data from point A to point B, they are essential components of modern design from improving operational efficiencies to providing real-time insights and ensuring compliance, seeks to harness the full potential of your data assets in today’s data-driven world Data pipelines are a must-have for organizations. Now let’s see different types of data pipelines.
Types of Data Pipelines
Data pipelines come in various types, each one catering to the different data processing needs. Here is the breakdown of data types in 3 main categories:

- Based on Data Processing
- Based on Deployment
- Based on Data Flow
Based on Data Processing
The data pipelines that are included based on the data processing is as follows:
Batch Processing Pipelines
These pipelines process data extensively on an intermittent basis, typically at night or on weekends. They are ideal for historical data analysis and reporting, handling large amounts of data efficiently.
Real-Time Processing Pipelines
This pipeline processes data as it comes in, enabling immediate insights and actions. They are important for applications that require real-time data analysis, such as fraud detection or bank monitoring.
Micro-batch Processing Pipelines
These pipelines process data in small batches, providing a balance between batch and real-time processing. They generate updates faster than batch processing but are slower than real-time, suitable for near-real-time analysis.
Based on Deployment
Data pipelines that are based on deployment are as follows:
Cloud-Native Data Pipelines
These pipelines use cloud platforms and services to process and store data. They offer scalability, flexibility, and low cost, making them popular in modern data architectures.
On-Premises Data Pipelines
This pipeline comes from within the organization’s own structure, providing greater control and security. However, it requires significant upfront investment and maintenance.
Based on Data Flow
There are two data pipelines based on the data flow and they are as below:
ETL
ETL stands for Extract, Transform and Load. This traditional method extracts data, transforms it into a staging area, and then places it in a final destination.
ELT
In ETL vs ELT, ELT stands for the Extract, Load and Transform. This emerging approach delivers data directly into the destination (such as a data lake or data warehouse) and processes it, often taking over the processing power of the cloud.
Choosing the right data pipeline depends on your specific data processing needs, the speed of data volume, and the real-time insights you desire. With this hopefully you are clear about the types of data pipelines available. It is important to understand the types of data pipelines for grasping how data pipelines work. Let’s see.

Hey!!
Looking for Data Engineering Service?
Revolutionize Your Data Infrastructure with Cutting-Edge Engineering Services from Aglowid IT Solutions!
How Data Pipelines Work?
To understand the process better, let’s apprehend it by example. Imagine you’re a college student writing research paper. For research paper you have to gather the information from variety of sources, it can be textbooks, online articles, or maybe you even conducted the surveys. But for analysing everything you need to organize it all. This is where data pipelines come into the play.
Data Pipelines are like the system that helps you for organizing all. They take raw data from different sources such as social media posts, web traffic or sensors reading. The stages are as follows:

Collecting
In this stage all the data of your research is gathered from the multiple places.
Cleaning
Imagine this as proofreading your data and removing any irrelevant data, grammatical mistake or any typos. Data pipelines make the data clean and format them in consistent and usable way.
Organizing
Consider keeping your information in a neat folder. Data pipelines store clean data in a fixed location, such as a data lake or data warehouse, making it easy to find and analyse.
Checking
You double-check your notes to make sure everything is correct. The data pipeline also verifies the data to ensure reliability. This entire process is automatic, making it easier to analyze data & get significant judgments from your research (or for businesses, make better decisions based on their data).
Data Pipeline Architecture
Data Pipelines architecture acts like the blueprint for how data moves through a system, ensuring its efficient collection, transformation, and delivery for analysis and decision-making. It works like a well-oiled machine which takes the raw data from various sources and transforms them into valuable insights. Let’s understand different data pipelines architecture examples.

Batch-Based Data Pipelines
Batch-based data pipelines excel in optimizing large datasets. Data is collected periodically (daily, weekly) and processed extensively, making it ideal for historical analysis and reporting. Think of it as if you were dealing with a whole stack of documents at once. While not ideal for real-time needs, batch pipelines offer cost savings and simplicity, making them a popular choice for tasks such as creating sales reports or analysing website traffic trends.
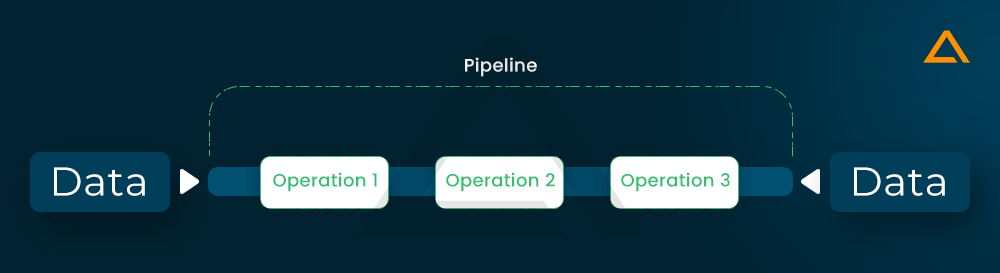
Next is the streaming data pipeline, so what does streaming pipeline do and how it works? Let’s find out.
Streaming Pipeline
Another example is the streaming data pipeline. In a streaming data pipeline, the data would be processed as it is from the point-of-sale system. The stream processing engine can transfer the results from the pipeline to other applications such as data warehouses, marketing applications and CRM, as well as the point-of-sale system itself.
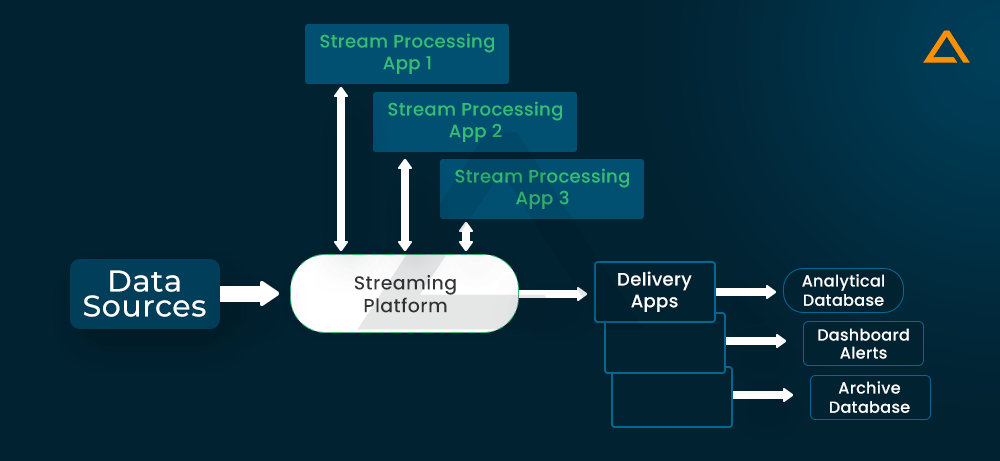
The data pipelines for stream processing are shown in the figure above. Where this can be processed and delivered to apps and solutions, the data stream of the stream processing framework is managed in this case.
Lambda Architecture
Third is Lambda Architecture, as it is the best of the two data pipeline frameworks. It combines streaming and batch pipelines into one design as it enables developers to capture historical batch analysis and real-time streaming use cases. Lambda Architecture is well-liked design in data contexts promotes raw data storage as one of its key features. It allows you to always use new data pipelines to fix any code errors in old pipelines or to set up new data destinations that support queries.
A more modern alternative to the Lambda architecture is the Kappa architecture. This is a more flexible architecture because it uses a stream processing layer for real-time and batch processing.
Another data pipelines comes from an open source project, Apache Beam. It provides a systematic approach to building data pipelines, with the pipeline itself to be deployed based on the platform the pipeline is installed in. Apache Beam provides a unified model for batch and streaming data processing, a portable and extensible approach which is especially helpful when considering multi-cloud and hybrid cloud deployments
How to Build a Data Pipeline?
Before you start planning your data pipeline architecture, it’s important to know important things like objectives and scalability requirements. There are a few things to keep in mind when designing your data pipeline:
Analytical requirements: At the end of the pipeline, figure out what kind of insights you want to get from your data. Are you using it for machine learning (ML), business intelligence (BI), or something else?
Volume: Consider the amount of data you will be monitoring and whether that amount may change over time.
Data types: Data pipeline solutions can have limitations depending on the nature of the data. Select the type of data to work with (structured, streaming, raw).

Determine Type of Data Pipeline
First, determine your needs, business goals, or target database requirements. You can use the list above to determine which data pipeline to use. For example, if you need to manage large amounts of data, you may need to create a batch data pipeline. Organizations that require real-time performance for their insights can instead benefit from stream processing.
Select Your Data Pipeline Tools
There are many types of data pipeline tools on the market. You can offer solutions that include end-to-end (whole process) pipeline management or integrate individual tools for a hybrid, individual solution. For example, if you are building a cloud data pipeline, you may need to connect cloud services (such as storage) to an ETL tool that prepares data for delivery to the destination.
Implement Your Data Pipeline Design
Once you implement your system, it’s important to plan for maintenance, scaling, and continuous improvement. Be sure to consider information security (InfoSec) in your plan to protect sensitive data as it passes through the pipeline. Typically, companies hire data engineers and architects to manage the design, implementation, and configuration of data pipeline systems.
Data Pipeline vs ETL: What’s the difference?
Often data pipelines and ETL (Extract, Transform, Load) pipelines are used interchangeably, but there are important differences between the two. An ETL pipeline is a type of data pipeline, characterized by its sequential process of extracting data, transforming and loading it into the data store This sequence is in the name “ETL”.

In contrast, data pipelines incorporate multiple processes and can include a variety of data movement processing tasks beyond the traditional ETL sequence for example, in addition to ETL, real-time streaming data processing in the data pipeline, data -May include enrichment, validation of data and data governance functions.
One of the key differences between ETL pipelines and data pipelines is the way data transformations are performed. In ETL pipelines, data transformations typically occur after data extraction and before data insertion. This sequential approach is well suited for traditional batch processing scenarios.
But the rise of cloud-native architecture and distributed computing technologies has made ELT (Extract, Load, Transform) pipelines popular. In ELT pipelines, data is first extracted and put into a cloud-based data warehouse or lake, the transformation though implemented later, typically using the scalability and computing power of cloud platforms.
Furthermore, although ETL pipelines typically refer to batch processing, data pipelines can support both batch and stream processing paradigms. Stream processing captures, manipulates and analyzes data in real time, allowing organizations to draw insights from data as it flows Although ETL pipelines typically involve data transformation, not all data pipelines require transformation steps.
However, transformation is necessary for most data pipelines to prepare data for analysis or use. Thus, while ETL pipelines represent a specific subset of data pipelines with predefined scheduling and transformation capabilities, data pipelines provide multiple data integration services and business processes with modern data-driven organizations the search is included.
When to Use Data Pipelines?
Data pipelines are used in a variety of contexts to facilitate the efficient management, processing and analysis of data. Here are some situations that are particularly useful in implementing a data pipeline:
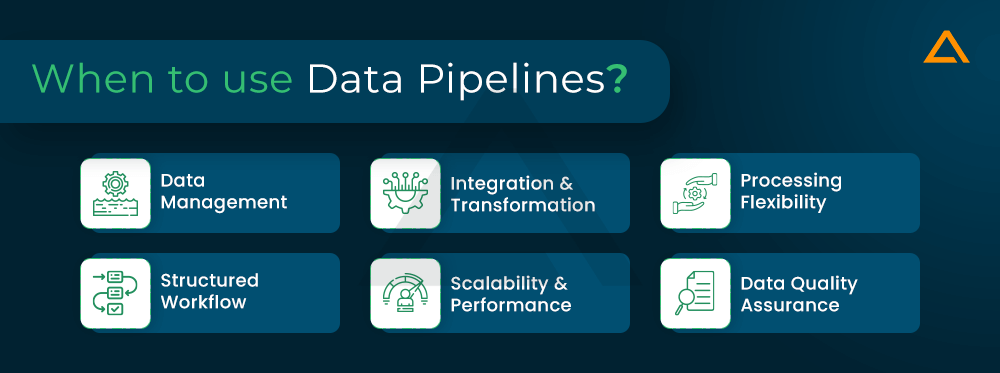
Data Management
Data pipelines play a crucial role in data management by automating the process of collecting, processing, and moving data from one place to another.
Integration and Transformation
Data pipelines seamlessly integrate and transform the data this will ensure the consistency and quality.
Processing Flexibility
Data pipelines support real-time and batch processing, meeting a variety of needs.
Structured Workflow
They provide a structured framework for efficiently managing complex data workflows.
Scalability and Performance
Data pipelines scale seamlessly and maintain high performance, even as data volumes increase.
Data Quality Assurance
Validation rules are enforced and data integrity is checked throughout the pipeline.
Wrapping Up!
In conclusion, data pipelines have become the backbone of modern data-driven organizations. They provide the necessary infrastructure to store, manipulate, and deliver data efficiently, and unlock the true potential of analytics and informed decision-making as the volume and complexity of data increases, data pipelines will continue to evolve, and will enable greater flexibility, scalability, and real-time capabilities. By understanding the types of data pipelines and how they are used, organizations can leverage these powerful technologies to gain a competitive advantage and thrive in an ever-changing data landscape.