Quick Summary:
Navigating data integration can be challenging. This blog will help you understand different data integration techniques and choose the best one for your project, whether you need real-time access, batch processing, or consolidation.
In this blog, we’re going to discuss📝
“Where there is data smoke, there is business fire.” This insightful quote by Thomas Redman, famously known as ‘the Data Doc,’ underscores the critical role of data integration and analytics in today’s data-driven world. In an era where data is often compared to fuel for business success, the ability to manage and integrate diverse data sources effectively has become crucial for organizations across all industries.
As businesses increasingly rely on data to drive decisions and strategies, ensuring that data is well-integrated and easily accessible is key to avoiding and addressing potential challenges. Just as a firefighter needs the right tools and techniques to manage a blaze, organizations need to choose the right data integration techniques to handle their complex data landscapes.
In this blog, we’ll explore various data integration techniques, each with its own strengths and applications, to help you determine which approach is ideal for your specific project needs.
What is the Purpose of Data Integration?
Data integration aims to bring together data from different sources into a unified view. This helps organizations make better decisions by providing accurate, consistent, and easily accessible information.

By combining data effectively, businesses can improve data quality, streamline processes, and ensure that they have a single source of truth. Ultimately, data integration supports better decision-making, enhances efficiency, and helps meet compliance requirements.
Why do We Need Different Types of Data Integration Techniques?
Different types of data integration techniques are necessary because each technique addresses specific challenges and requirements related to data management.
Here’s why various data integration methods are needed:

1. Variety of Data Sources
Data comes from different sources—databases, APIs, cloud services, etc. Different techniques help manage these diverse sources, handling varying formats and structures.
2. Volume and Complexity
The amount and complexity of data can vary greatly. Techniques like data warehousing handle large, complex datasets, while simpler methods work well for smaller, less complex data.
3. Real-Time vs. Batch Needs
Some applications require real-time data (e.g., live analytics), while others can process data in batches (e.g., weekly reports). Different techniques cater to these needs, providing solutions for both real-time and batch processing.
4. Performance and Scalability
Techniques vary in how they handle performance and scalability. Some methods, like ETL, are designed for high performance with large volumes, while others, like data virtualization, offer flexibility and real-time access.
5. Resource Constraints
The availability of time, budget, and infrastructure can impact the choice of technique. Some methods are more cost-effective and easier to implement, while others require more resources.
By choosing the appropriate technique based on these factors, organizations can effectively integrate their data to meet specific needs and ensure efficient data management.
Popular Data Integration Techniques and Methods
Data has always been essential, but its value as an asset has significantly increased with modern data integration techniques. In the past, methods like Manual Data Integration were basic, involving error-prone and time-consuming processes.
Today, advanced techniques such as ETL (Extract, Transform, Load), API Integration, and Change Data Capture (CDC) enable seamless, real-time data integration across multiple sources. These methods unlock powerful insights and drive innovation, making data more valuable than ever.
Here are some of the most popular data integration methods and techniques with their specific use cases, limitations and benefits:
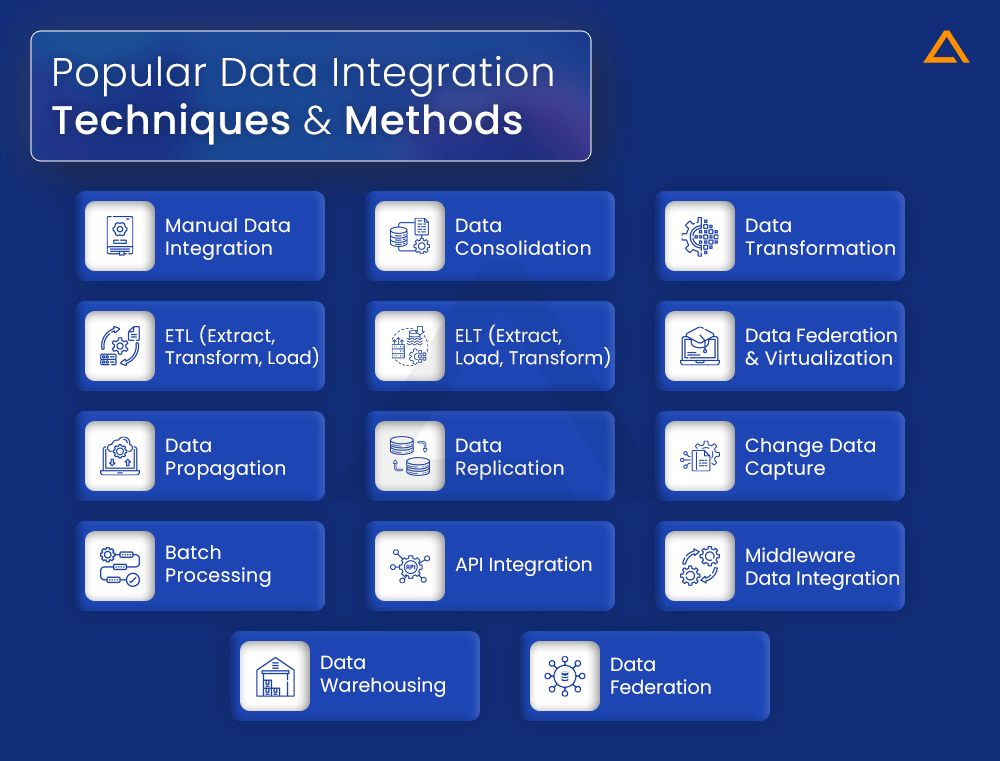
Manual Data Integration
- Main Purpose: Involves manually combining data from different sources, often using spreadsheets or similar tools.
- Ideal Use Case: Suitable for small-scale integrations or one-off projects.
Pros & Cons:
| Pros | Cons |
| Low cost and easy to implement | Time-consuming and error-prone |
| Offers complete control over the process | Not scalable for large datasets |
Process:
- Collect data from various sources.
- Manually cleanse and merge data.
- Store or use data for the intended purpose.
Tools Used:
- Microsoft Excel
- Google Sheets
- Access
Data Consolidation
- Main Purpose: Combines data from various sources into a single, unified data storage system.
- Ideal Use Case: Best for organizations needing a centralized data repository, often for analytics or reporting.
Pros & Cons:
| Pros | Cons |
| Centralized access to all data | Time-consuming for large-scale data |
| Simplifies data management | Potential data redundancy issues |
Process:
- Extract data from multiple sources.
- Cleanse and transform data as needed.
- Load data into a consolidated storage system.
Tools Used:
- Apache Nifi
- Talend
- Informatica
Data Transformation
- Main Purpose: Converts data from its original format to a format suitable for the target system.
- Ideal Use Case: Best for scenarios requiring significant data restructuring.
Pros & Cons:
| Pros | Cons |
| Enables data standardization | Can be resource-intensive |
| Supports complex data manipulations | May slow down the integration process |
Process:
- Extract raw data.
- Apply necessary transformations (cleansing, normalization, etc.).
- Load transformed data into the target system.
Tools Used:
- Talend
- Apache Spark
- Informatica PowerCenter
ETL (Extract, Transform, Load)
- Main Purpose: To extract data from various sources, transform it into a uniform format, and load it into a target data warehouse or database.
- Ideal Use Case: Suitable for complex data transformations and batch processing needs.
Pros & Cons:
| Pros | Cons |
| Handles complex transformations | Can be time-consuming for large datasets |
| Supports extensive data cleansing | Batch processing might not support real time data needs |
| Centralizes data in a single repository | – |
Process:
- Extract: Collect data from multiple sources.
- Transform: Cleanse, standardize, and aggregate data.
- Load: Insert transformed data into the target system.
Tools Used:
- Apache Airflow
- Informatica
- Talend
Also Read: ETL vs ELT: Navigating the Data Integration Landscape
ELT (Extract, Load, Transform)
- Main Purpose: To extract data from sources, load it directly into the target system, and then transform it within the target system.
- Ideal Use Case: Best for modern cloud-based data warehouses with high processing power.
Pros & Cons:
| Pros | Cons |
| Leverages the target system’s processing power | Transformation process can be complex and resource-intensive |
| Faster initial load times compared to ETL | Requires robust target system infrastructure |
| Can handle large volumes of data efficiently | – |
Process:
- Extract: Collect data from various sources.
- Load: Insert raw data into the target system.
- Transform: Process and convert data within the target system.
Tools Used:
- Google BigQuery
- Snowflake
- Azure Synapse
Data Federation & Virtualization
- Main Purpose: Provides a unified view of data from multiple sources without physically consolidating it.
- Ideal Use Case: Suitable for organizations needing real-time access to distributed data.
Pros & Cons:
| Pros | Cons |
| Real-time data access | Performance may suffer with complex queries |
| No need to move data physically | Limited transformation capabilities |
Process:
- Connect to data sources.
- Query data from multiple sources.
- Present a unified data view.
Tools Used:
- Denodo
- Dremio
- IBM Data Virtualization
Data Propagation
- Main Purpose: Distributes data across multiple systems to ensure synchronization and consistency.
- Ideal Use Case: Effective for environments needing data synchronization between different systems.
Pros & Cons:
| Pros | Cons |
| Ensures consistency across systems | Can be complex to implement and manage |
| Supports real-time or near-real-time updates | May incur latency during propagation |
Process:
- Detect changes in source data.
- Propagate changes to other systems.
- Synchronize and update the target systems.
Tools Used:
- Apache Kafka
- Oracle GoldenGate
- AWS DataSync
Data Replication
- Main Purpose: To copy data from one system to another, keeping the target system synchronized with the source.
- Ideal Use Case: Effective for backup, disaster recovery, and maintaining synchronized data copies.
Pros & Cons:
| Pros | Cons |
| Ensures data availability and redundancy | Can lead to data redundancy |
| Supports high availability and disaster recovery | May incur additional storage costs |
Process:
- Extract: Identify changes or data to be replicated.
- Transfer: Copy data to the target system.
- Synchronize: Update and synchronize the target system with the source data.
Tools Used:
- Oracle GoldenGate
- IBM InfoSphere Data Replication
- Microsoft SQL Server Replication
Change Data Capture (CDC)
- Main Purpose: To identify and capture changes made to data in real-time, ensuring that the target system reflects these changes.
- Ideal Use Case: Effective for real-time data synchronization and updating data warehouses.
Pros & Cons:
| Pros | Cons |
| Provides real-time data updates | Requires continuous monitoring of source changes |
| Reduces the need for full data refreshes | Can be complex to implement and manage |
Process:
- Capture: Monitor and identify changes in the source data.
- Extract: Extract changed data.
- Apply: Apply changes to the target system.
Tools Used:
- Debezium
- Oracle CDC
- SQL Server CDC
Batch Processing
- Main Purpose: To process large volumes of data at scheduled intervals.
- Ideal Use Case: Suitable for processing large datasets that don’t require real-time updates.
Pros & Cons
| Pros | Cons |
| Handles large volumes of data efficiently | Not ideal for real-time or near-real-time data needs |
| Suitable for non-time-sensitive operations | Processing delays can impact decision-making |
Process:
- Collect: Gather data at scheduled intervals.
- Process: Execute data processing tasks in bulk.
- Store: Save processed data to the target system
Tools Used:
- Apache Hadoop
- Apache Spark
- IBM DataStage
API Integration
- Main Purpose: To connect different systems and applications using Application Programming Interfaces (APIs) to exchange data.
- Ideal Use Case: Ideal for integrating applications with real-time data exchanges and microservices.
Pros & Cons:
| Pros | Cons |
| Supports real-time data integration | Requires development effort for API creation and management |
| Facilitates integration between disparate systems | Potential for API rate limits and security concerns |
Process:
- Develop: Create or use existing APIs to access data.
- Connect: Integrate APIs with systems and applications.
- Exchange: Transfer data between systems via APIs.
Tools Used:
- Apigee
- Postman
- Swagger
Middleware Data Integration
- Main Purpose: Uses middleware to connect and integrate disparate systems.
- Ideal Use Case: Best for integrating legacy systems with modern platforms.
Pros & Cons:
| Pros | Cons |
| Bridges different technologies | Adds complexity and potential overhead |
| Scalable integration solution | May require extensive configuration |
Process:
- Connect middleware to source and target systems.
- Translate data formats and protocols as needed.
- Facilitate data exchange between systems.
Tools Used:
- MuleSoft
- TIBCO
- IBM WebSphere
Data Warehousing
- Main Purpose: Consolidates and stores large volumes of data for analysis and reporting.
- Ideal Use Case: Suitable for organizations needing structured, historical data for business intelligence.
Pros & Cons:
| Pros | Cons |
| Centralized repository for analytics | Requires significant storage and processing resources |
| Supports complex querying and reporting | Not ideal for real-time data needs |
Process:
- Extract data from operational systems.
- Transform and cleanse data.
- Load data into the warehouse for analysis.
Tools Used:
- Snowflake
- Amazon Redshift
- Google BigQuery
Data Federation
- Main Purpose: To combine data from multiple sources into a single, accessible interface.
- Ideal Use Case: Ideal for integrating data from heterogeneous systems into a single query-able interface.
Pros & Cons:
| Pros | Cons |
| Provides a unified data access layer | May involve performance overhead due to data querying across systems |
| Supports querying across multiple data sources | Limited to the capabilities of the federation tool |
| Minimizes data redundancy | – |
Process:
- Connect: Integrate disparate data sources.
- Query: Use a unified query interface to access data.
- Present: Aggregate and display data from various sources.
Tools Used:
- Cisco Data Virtualization
- SAP HANA Smart Data Access.

Hey!!
Looking for Data Engineer?
Hire Aglowid for top-notch data engineering. Our experts build efficient data systems that help you make better decisions.
How to Find the Best Data Integration Technique for Your Requirements?
Choosing the right data integration technique is crucial for ensuring data quality, consistency, and efficient use. Here’s a step-by-step guide to help you determine the best approach for your specific needs:

1. Assess Your Data Integration Goals
Before diving into the technical aspects of data integration, it’s crucial to clearly define your objectives. Understanding what you aim to achieve with your data integration efforts will guide your decision-making process and ensure that the chosen techniques align with your goals.
Here are some key areas to consider:
- Data Quality: Do you need to clean, standardize, or validate data?
- Data Consistency: How important is ensuring data integrity across different systems?
- Data Accessibility: Do you need to make data accessible to various users or applications?
- Data Security: What are your data security and compliance requirements?
2. Analyze Your Data Sources
The nature of your data sources plays a significant role in determining the most suitable integration technique. Different types of data require different approaches, and understanding the specifics of your data will help you select the best method for integration.
Consider the following factors:
- Data Types: Are your data sources structured, semi-structured, or unstructured?
- Data Volume: How much data do you need to integrate?
- Data Velocity: How frequently does the data change?
3. Consider Your Existing Infrastructure
Your current IT infrastructure will influence your choice of integration techniques. The systems and tools you already have in place can either facilitate or constrain your options, so it’s important to evaluate your existing environment thoroughly.
Focus on the following aspects:
- Systems and Applications: What systems and applications are involved in the integration process?
- Data Warehouses or Data Lakes: Do you have existing data warehouses or data lakes?
- Integration Tools: Are there any existing integration tools or platforms?
4. Evaluate Integration Techniques
Once you’ve assessed your goals, data sources, and infrastructure, it’s time to evaluate the various data integration techniques available. Each method has its strengths and weaknesses, and the best choice will depend on your specific requirements.
Here’s a breakdown of some common techniques:
| Technique | Main Purpose | Ideal Use Case |
| Manual Data Integration | Combine data manually using spreadsheets. | Small scale projects |
| Quick integrations | ||
| Scenarios where automation isn’t feasible | ||
| Merging data from different departments | ||
| Creating simple reports | ||
| Data Consolidation | Combine data into a single storage system. | Centralized data repository for analysis |
| Aggregating data from various sources | ||
| Comprehensive business intelligence | ||
| Data Transformation | Convert data to a target format. | Significant data restructuring |
| Data preparation for reporting | ||
| Analytics and data integration | ||
| ETL (Extract, Transform, Load) | Extract, transform, and load data into a target system. | Complex data transformations |
| Batch processing needs | ||
| Loading data into data warehouses | ||
| Analytical platforms on a scheduled basis | ||
| ELT (Extract, Load, Transform) | Extract data, load it, then transform within the target. | Modern cloud-based data warehouses |
| Handling large volumes of data | ||
| When the target system can handle transformations post-load | ||
| Data Federation | Provide a unified view of distributed data. | Realtime access to data from multiple sources |
| Creating a single interface for querying | ||
| Avoiding physical data consolidation | ||
| Data Propagation | Distribute data to ensure synchronization. | Realtime or near real-time data consistency |
| Synchronizing data across different systems | ||
| Reflecting changes quickly across systems | ||
| Data Replication | Copy data to keep systems synchronized. | Backup and disaster recovery |
| High availability | ||
| Maintaining synchronized data copies | ||
| Change Data Capture (CDC) | Capture real-time data changes. | Realtime data synchronization |
| Continuous updating of data warehouses | ||
| Timely reflection of data changes | ||
| Batch Processing | Process large volumes of data at intervals. | Large dataset processing |
| Scheduled data processing tasks | ||
| Generating nightly reports | ||
| Largescale data transformations | ||
| API Integration | Connect systems using APIs. | Realtime data exchanges |
| Integrating modern applications | ||
| Microservices integration | ||
| Dynamic system interactions | ||
| Middleware Data Integration | Connect and integrate different systems. | Integrating legacy systems with modern applications |
| Bridging different technologies | ||
| Complex IT environments | ||
| Data Warehousing | Store and analyze large volumes of data. | Structured, historical data for analysis |
| Centralizing data for business intelligence | ||
| Comprehensive reporting |
5. Consider Factors Affecting Your Choice
Choosing the right data integration technique involves more than just technical considerations. Practical factors such as cost, scalability, performance, and maintainability will also play a critical role in your decision. It’s essential to weigh these factors carefully to ensure that your integration solution is not only effective but also sustainable.
Key considerations include:
- Cost: Evaluate the costs associated with different techniques, including licensing fees, hardware requirements, and maintenance.
- Scalability: Ensure the chosen technique can handle future growth in data volume and complexity.
- Performance: Consider the speed and efficiency of the integration process.
- Maintainability: Evaluate the ease of managing and updating the integration solution.
6. Pilot and Evaluate
Before fully committing to a particular integration technique, it’s wise to pilot it in a controlled environment. This allows you to test the approach, measure its performance, and gather feedback from stakeholders. A pilot phase can provide valuable insights and help you fine-tune your integration strategy before full-scale implementation.
Key steps include:
- Implement a Proof of Concept: Test different techniques in a controlled environment to assess their suitability.
- Measure Performance: Track key metrics such as data quality, integration speed, and resource utilization.
- Gather Feedback: Involve stakeholders to get their input on the effectiveness of the chosen technique.
7. Additional Considerations
Beyond the core steps of selecting and evaluating data integration techniques, there are additional factors that may impact your decision. These considerations can help ensure that your integration efforts are aligned with broader business goals and compliance requirements.
Important areas to explore include:
- Cloud vs. On-Premises: Evaluate whether cloud-based or on-premises integration solutions are more suitable for your needs.
- Data Governance: Implement data governance policies to ensure data quality, security, and compliance.
- Integration Tools: Consider using specialized integration tools to streamline the process and reduce development effort.
By following these steps and considerations, you can select the most appropriate data integration technique for your project, ensuring that your data is well-managed, accessible, and valuable for your organization’s needs.
Data Integration Best Practices to Ensure Better Results
Here are some additional best practices to enhance your data integration efforts and achieve seamless, efficient results. By following these guidelines, you can ensure that your data integration process is effective, secure, and scalable, ultimately leading to better decision-making and improved business outcomes.

- Define Clear Objectives: Understand your data integration goals and align them with your business objectives.
- Choose the Right Technique: Select a technique that fits your data type, volume, and processing needs.
- Prioritize Data Quality: Implement rigorous data cleansing and validation processes to maintain data accuracy.
- Ensure Scalability: Opt for solutions that can scale with your data growth and evolving needs.
- Monitor and Optimize: Continuously monitor the performance of your integration processes and optimize as necessary.
- Maintain Data Security: Implement strong security measures to protect sensitive data throughout the integration process.
- Document Your Processes: Keep detailed documentation of your integration workflows to facilitate troubleshooting and future modifications.
Wrapping Up
Selecting the right data integration technique is pivotal for optimizing data management and achieving strategic goals. By carefully evaluating your data sources, infrastructure, and specific needs, you can choose an approach that enhances efficiency and drives better decision-making.
For those looking to navigate this complex landscape effectively, partnering with skilled professionals can make a significant difference. Consider exploring options for hiring a data analyst to support your integration efforts and ensure you make the most out of your data resources. Their expertise could be invaluable in achieving seamless and effective integration.